NGINX-Performancemetriken mit Prometheus
Prometheus ist eine Kombination aus Monitoring-Werkzeug und Zeitreihen-Datenbank, die ich in den letzten Monaten sehr zu schätzen gelernt habe. Dieser Artikel zeigt, wie Prometheus genutzt werden kann, um verschiedene Webserver-Metriken (ohne Konfigurationseingriff) in Prometheus nutzbar zu machen.
Grundsätzlich werden Metriken nach dem Pull-Prinzip in Prometheus importiert.
Dies bedeutet, dass ein zu überwachender Service einen HTTP-Endpunkt anbieten
muss, der von Prometheus dann in regelmäßigen Intervallen (standardmäßig 15
Sekunden) abgefragt werden kann. Dieser Endpunkt (beispielsweise
http://<service-name>/metrics) muss dann eine Antwort mit entsprechenden
Zeitreihendaten ausliefern:
http_response_count_total{application="my-application"} 12423
http_response_time_seconds{application="my-application"} 1832745
Dies funktioniert ausgezeichnet in Microservice-Architekturen – hier kann jeder
Service einen einzelnen /metrics-Endpunkt implementieren, der alle denkbaren
Kennzahlen auswirft.
Das Problem
Nicht so gut funktioniert dieser Ansatz, wenn Prometheus zur Überwachung von Performance-Metriken einer (älteren) Web-Applikation genutzt werden soll, die in einem “klassischen” LEMP-Stack (Linux, NGINX, MySQL, PHP) betrieben wird. Dies liegt daran, dass eine PHP-Applikation üblicherweise nicht über solche Metriken wie Anzahl der verarbeiteten Requests oder die durchschnittliche Request-Dauer verfügt (oder sie selbst erheben und dann in einer Datenbank persistieren müsste).
Für die Integration von NGINX-Webservern mit Prometheus gibt es bereits mehrere
Konnektoren im Internet – diese werten jedoch entweder nur die Informationen
der NGINX-Statusseite aus, die über das Modul ngx_http_stub_status_module
angeboten wird (nicht detailliert genug für meinen Anwendungsfall), oder
erfordern eine Umkonfiguration des Webservers, um einen neuen Logging-Server
anzusprechen (zu invasiv für meine gehegte und gepflegte Alt-Applikation).
Meine Lösung
Meine Lösung des Problems besteht nun in einem eigenen Exporter, der
Performance-Metriken aus bestehenden NGINX-Accesslogs generieren kann. Dieser
steht als Open Source auf Github zur Verfügung, und stellt einem
Prometheus-Server auf Grundlage einer bestehenden access.log-Datei diverse
Metriken zur Verfügung:
- Anzahl der verarbeiteten Requests pro Request-Methode und Status
- Summe der für die bisher verarbeiteten Requests notwendige Zeit, pro Methode und Status (zusammen mit der Anzahl kann hieraus die durchschnittliche Antwortzeit über den zeitlichen Verlauf ermittelt werden)
- Summe der “Upstream Time”, also der Zeit, die NGINX damit zugebracht hat, auf PHP-FPM oder andere FastCGI-Module zu warten
- Diverse Quantile der Antwortzeit und Upstream Time
Konfiguration
Der NGINX-Exporter wird über eine HCL-Konfigurationsdatei konfiguriert. In der Konfigurationsdatei können mehrere “Namespaces” konfiguriert werden – diese werden dann als separate Metriken exportiert. Nachfolgend ein kurzes Beispiel für eine solche Konfigurationsdatei:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
listen {
port = 4040
address = "0.0.0.0"
}
namespace "app1" {
format = "$remote_addr - $remote_user [$time_local] \"$request\" $status $body_bytes_sent \"$http_referer\" \"$http_user_agent\" \"$http_x_forwarded_for\""
source_files = ["/var/log/nginx/access.log"]
labels {
app = "my-application"
environment = "production"
foo = "bar"
}
}
Beim Start des Exporters startet dieser einen eigenen HTTP-Server, der auf der
konfigurierten IP-Adresse und Port lauscht (standardmäßig 0.0.0.0:4040). Über
die URL http://<IP>:4040/metrics können dann von Prometheus die entsprechenden
Performance-Metriken abgegriffen werden.
Der Namespace-Name (hier app1) wird später in den Namen der exportierten
Metriken übernommen – also beispielsweise app1_http_response_time_seconds.
Das Format (format) gibt das Format an, in dem NGINX die Access-Logs schreibt
(für mehr Informationen dazu sei auf die Dokumentation verwiesen).
Start des Exporters
Der eigentliche Exporter ist ein statisch kompiliertes Go-Binary, welches nach dem Herunterladen sofort installiert werden kann:
wget https://github.com/martin-helmich/prometheus-nginxlog-exporter/releases/download/v1.0.0/prometheus-nginxlog-exporter
./prometheus-nginxlog-exporter -config-file /pfad/zur/config.hcl
Um sicherzustellen, dass der Exporter beim Systemstart automatisch startet,
kann eine entsprechende systemd-Unit konfiguriert werden (ab Debian 8, Ubuntu
16.04 oder CentOS 7). Diese kann platziert werden unter /etc/systemd/system/prometheus-nginxlog-exporter.service:
1
2
3
4
5
6
7
8
9
10
11
12
[Unit]
Description=NGINX metrics exporter for Prometheus
After=network-online.target
[Service]
ExecStart=/usr/local/bin/prometheus-nginxlog-exporter -config-file /etc/prometheus-nginxlog-exporter.hcl
Restart=always
ProtectSystem=full
CapabilityBoundingSet=
[Install]
WantedBy=multi-user.target
Beachtet, dass diese Unitfile davon ausgeht, dass das Binary unter
/usr/local/bin/prometheus-nginxlog-exporter und die Konfigurationsdatei unter
/etc/prometheus-nginxlog-exporter.hcl liegt. Diese Pfade können natürlich nach
Bedarf angepasst werden.
Das Ergebnis
Ich betreibe den prometheus-nginxlog-exporter nun seit einiger Zeit schon
produktiv. Insbesondere zusammen mit Grafana lassen sich wunderbare
Auswertungen und Monitoring-Dashboards erstellen:
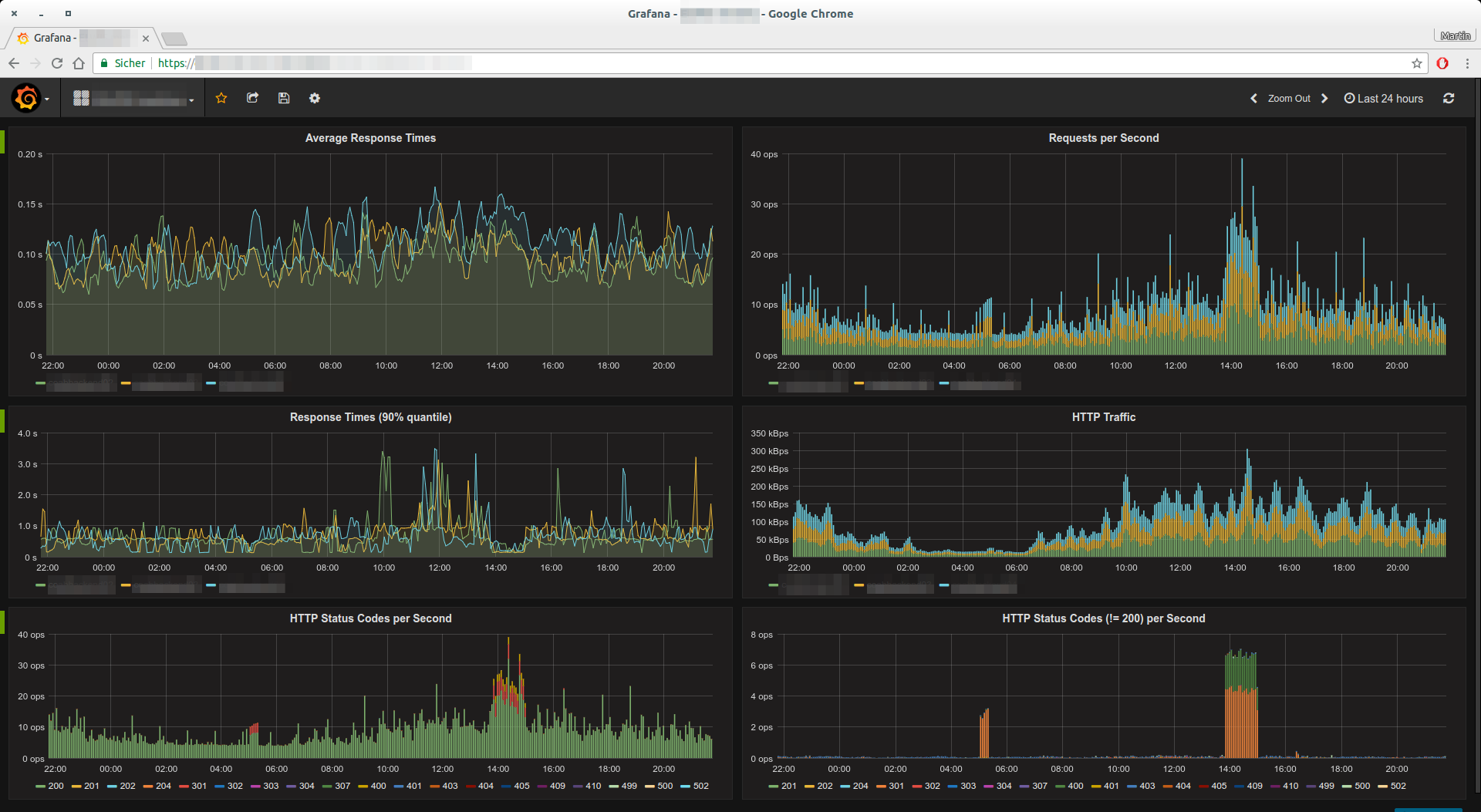
Die Diagramme im obigen Screenshot wurden aus den folgenden Prometheus-Queries generiert:
- Durchschnittliche Antwortzeit:
sum(rate(app_http_response_time_seconds_sum[5m])) by (instance) / sum(rate(app_http_response_time_seconds_count[5m])) by (instance) - Anfragen pro Sekunde:
sum(rate(app_http_response_time_seconds_count[1m])) by (instance) - Antwortzeit (90%-Quantil):
app_http_response_time_seconds{quantile="0.9",method="GET",status="200"} - HTTP-Traffic:
sum(rate(app_http_response_size_bytes[5m])) by (instance) - Statuscodes pro Sekunde:
sum(rate(app_http_response_count_total[1m])) by (status)